GPU Controlled Rendering Using Compute & Indirect Drawing#
In the past couple of years, rendering engines have been moving more and more towards calculating the rendering workloads on the GPU (using compute shaders). We have a couple of benefits with this approach:
With minimal CPU intervention, the latencies between the CPU and GPU are reduced, enhancing overall performance
By minimizing driver overhead, CPU bottlenecks are avoided, enabling the GPU to operate at its optimal capacity. As a result, the CPU can allocate resources to other meaningful tasks.
But we need to also keep in mind that this comes at a cost at extra preparation and storing the entire scene data on GPU to make the rendering decisions.
Draw Indirect#
The key aspect of the idea centers around the utilisation of Draw Indirect support within the graphics APIs. We can perform Indirect Drawing using OpenGL, Vulkan and DX11/DX12. However, their optimal performance is achieved when used on Vulkan or DX12 due to their underlying ability to control low-level memory management and compute barriers.
The allocation of our graphics workload to the GPU on the host side (application) is frequently determined based on factors such as the number of primitives to be drawn, the number of instances, and the vertex and index count. This allocation is achieved through the usage of vkDrawX() commands. In contrast, the indirect drawing commands obtain their draw calls from a buffer, which is ideally stored in device local memory. Rather than executing individual draw commands with the host providing the index base, index count, and instance numbers upon invocation, the indirect commands are associated with a buffer that contains an arbitrary number of draw commands. Since the draw commands are stored in a buffer accessible by the GPU, it becomes feasible for our compute shaders, for instance, to manipulate the draw commands issued before they are consumed by our Draw Indirect stage. We can perform tasks such as scene traversal, sorting, and culling offloading from the CPU to the GPU.
As for demonstrating this technique, we’ll take a look at a Vulkan implementation that showcases GPU object-based culling using indirect drawing and compute shader on our Tile-Based Deferred Rendering (TBDR) architecture. This can be a sensible approach to reduce the load on the vertex, geometry, and tessellation stages. The implementation performs GPU object based culling (frustum) using compute shaders and indirect drawing. GPU based culling through indirect drawing offers significant advantages over conventional CPU-based frustum culling techniques as we know that GPUs have orders of magnitude higher performance than CPU executing data parallel algorithms.
On PowerVR TBDR architectures, with their tile-based rendering approach, which already provides benefits such as hidden surface removal (HSR) and reduced overdraw by efficiently processing only visible pixels within a tile. However, by incorporating object-based culling, you can further optimize the rendering pipeline by reducing unnecessary computations and memory bandwidth consumption for objects that are not visible.
Let us take a look at the rendering pipeline and setup required for the implementation.
Rendering Pipeline#
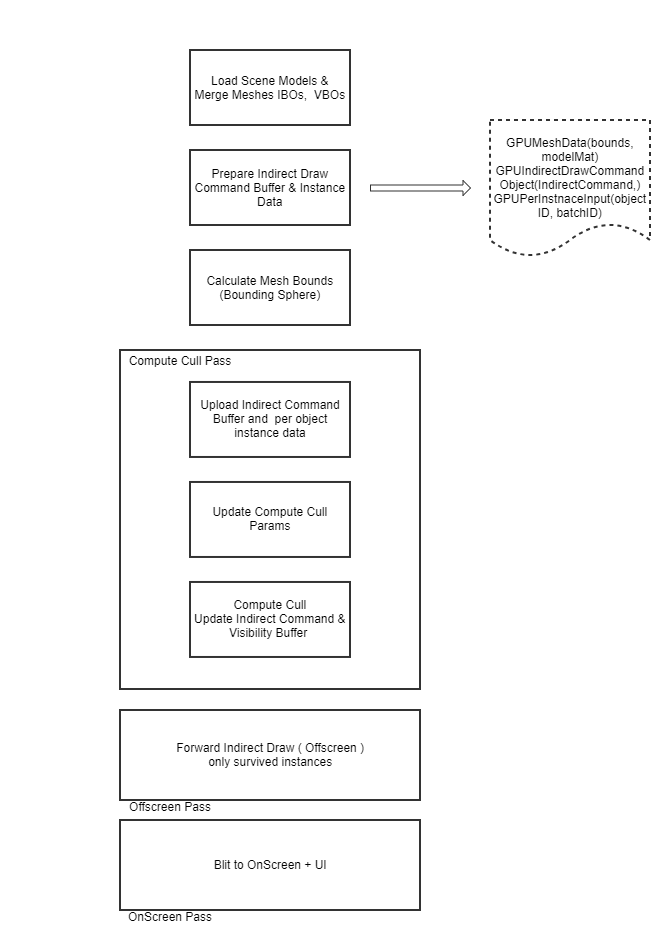

GPU Object Based Culling (Frustum)#
This implementation showcases GPU based frustum culling using indirect draw and compute shaders. This technique tries to improve rendering performance by reducing the number of objects processed by the GPU that are outside the view frustum. The frustum represents the portion of the 3D scene that is visible to the camera. Traditionally, CPU-based frustum culling involves iterating over each object in the scene and checking if it intersects with the view frustum. This process can be time-consuming, especially when dealing with a large number of objects. To offload some of this work to the GPU, indirect draw commands and GPU buffers are used with compute shader.
Next, let’s look at some of the possible benefits of implementing object-based culling on TBDR architectures for mobile devices:
Reduced Tiler Processing: By eliminating the rendering of occluded objects early enough, you can save significant processing power and memory bandwidth consumption in the Tiler stage. Tiler stage basically deals with vertex processing, all the projection, clipping and culling and tiling/binning operations.
Reduced memory footprint: By omitting the rendering of non-visible objects, we can effectively decrease the memory usage associated with our parameter buffers.
Improved efficiency: By minimizing unnecessary computations, you can increase the efficiency of the rendering pipeline and potentially achieve higher frame rates and better power efficiency.
Note
As mentioned earlier, these benefits come at a cost of extra preparation on the CPU side during initialisation. Indirect draw commands need to be generated based on scene complexity and needs to be sorted based on material type when using different materials and while trying to go as much as bindless to have as less CPU intervention as possible. Also, while we need to store the entire scene data on the GPU early at hand for it to make the rendering decisions. Checking device memory limits and scene complexity and memory requirements would be a good exercise to follow before employing GPU controlled culling techniques.
Performance Analysis with PVRTune#
The analysis has been carried out on our BXM-8-256 powered GPU.
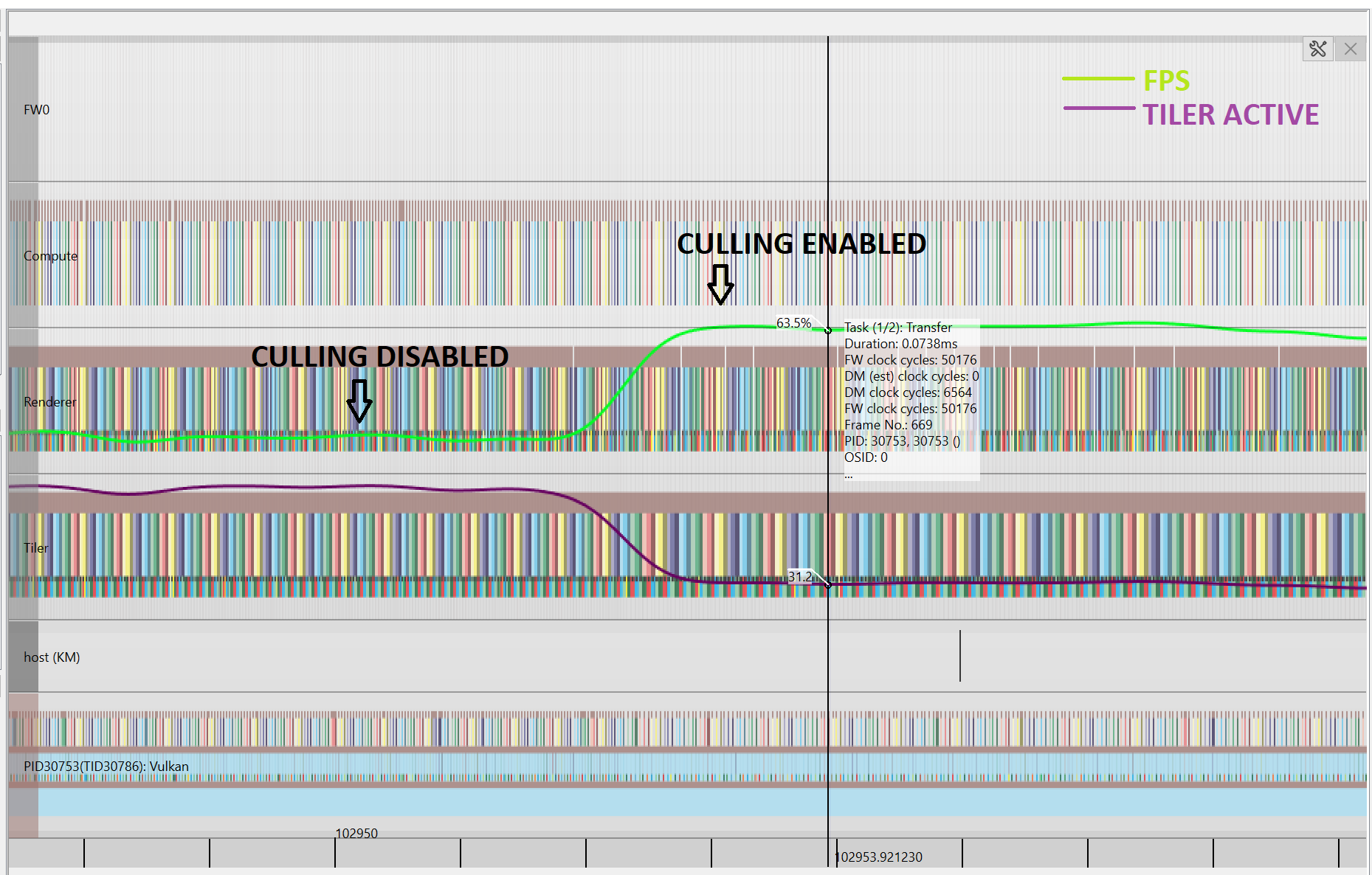
As we can see from the PVRTune recording above which shows profiling information of several frames. In the first half of the trace, the GPU Compute Culling is disabled and where we can observe the FPS is relatively low compared to when it is enabled in the 2nd half. Also, the Tiler Activity seems to be quite high compared to the culling enabled mode. One might question the very processing time overhead that our GPU Compute Cull pass might introduce. In this scenario it takes ~0.031ms to perform frustum culling for the entire scene. Of course, it depends on what more one wants offload from CPU to GPU as we discussed earlier. In this very example we are just showcasing and performing a simple early frustum cull.
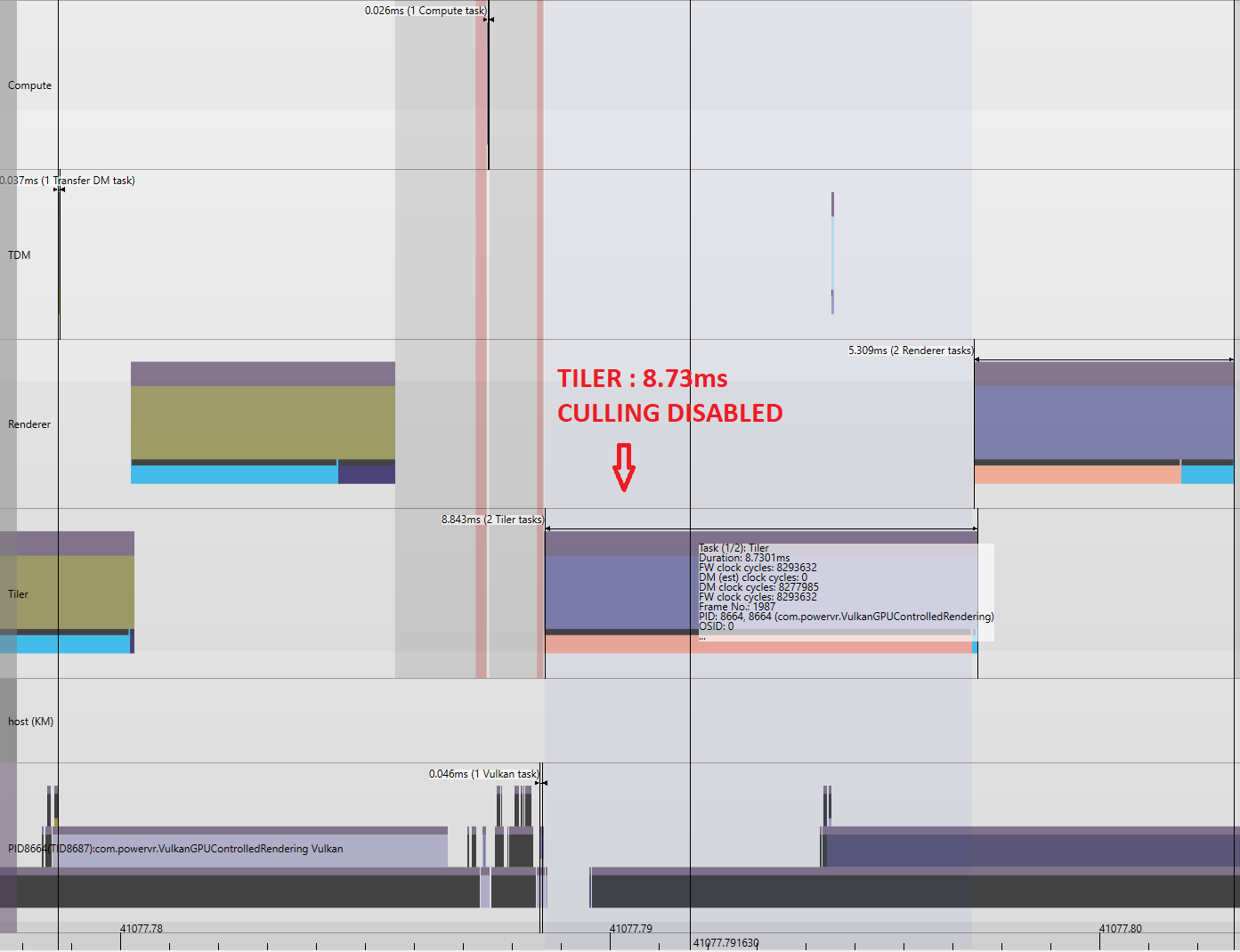
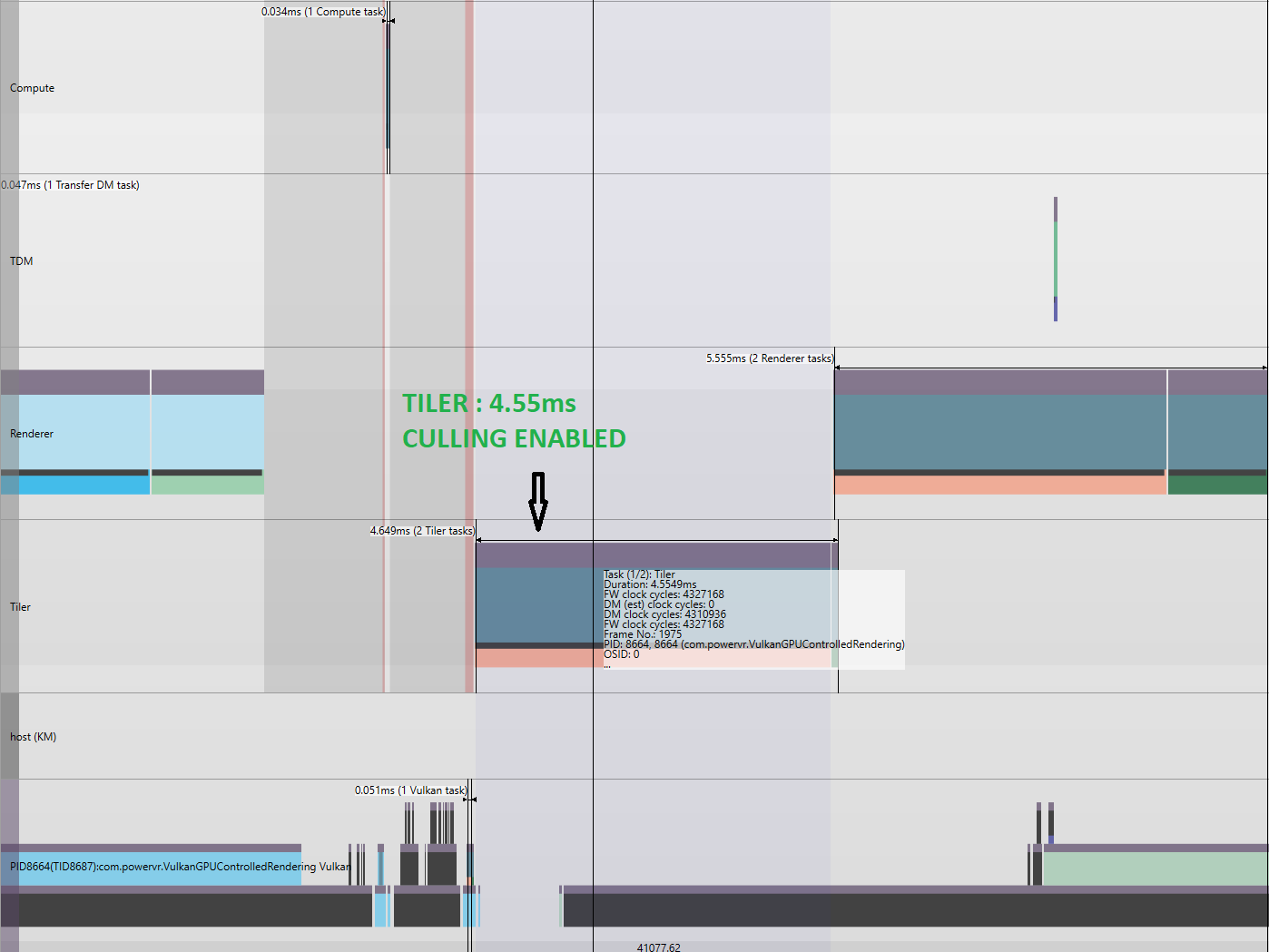
For the given workload, when we have the GPU culling disabled, the tiler spends 8.73ms of total frame budget just processing the geometry. This includes both, the geometry that’s going to generate fragments for the final image and the ones which is going to be eventually discarded with our hardware culling/clipping stage that are outside of our view frustum. We could observe significant reduction in the tiler time when culling is enabled. The Tiler time can be seen reduced to 4.55ms.
For more details on the implementation and code please refer to the PowerVR SDK.